Scaling SQLite to 4M QPS on a single server (EC2 vs Bare Metal)

Expensify has an unusual technology stack in many ways. For example, we don't use DNS internally — just configuration-managed /etc/hosts files — and it works great. Similarly, we only make limited use of AWS — instead hosting our own hardware for the web and database layer — and it works great. But most surprising of all is that we don't use MySQL or Postgres — instead using none other than SQLite — and it works great.

Granted, it's not SQLite by itself. We've wrapped it in a custom distributed transaction layer named Bedrock, which is open sourced and available here: www.bedrockdb.com. It's not just the workhorse behind our core database, but also powers our mission-critical job queue, and provides a locally-hosted replicated caching layer. The more important the function, the more it depends on Bedrock.
Accordingly, given the explosive growth of 2017, upgrading the servers that power Bedrock has been a top priority — along with upgrading Bedrock (and with the help of incredible the SQLite team, SQLite itself) to take advantage of all that hardware. To that end we're just about to roll out an entirely new generation of self-hosted hardware with the following basic specs:
1TB of DDR4 RAM
3TB of NVME SSD storage
192 physical 2.7GHz cores (384 with hyperthreading)
This is a monster server, nearly the biggest that is possible to buy that runs on a stock Linux kernel (without getting into "supercomputer" territory), and we're getting a bunch of them. But hardware alone isn't enough. To be clear, the above specs would be pointless for most databases, as almost nothing scales to handle this kind of hardware well — and almost nobody tries.
Why we are trying
The traditional wisdom is that you should always build "out" not "up", meaning it's better to have a large number of small servers than a relatively small number of large servers.
Most companies will "shard" their data into separate servers, such as to put 1000 customers on each server — and then just route each customer to the right server when they sign in. That design works super well for many applications, and means you never need to learn how to manage a big database — just a lot of small databases.
Expensify is a bit different in that there is no sharding — and no clear "faultline" on which to do it. Every single user can share expenses with every single other user, regardless of where they work.
This is a critical feature that enables us to offer such good support for large accounting firms that manage hundreds or even thousands of clients: when a company takes on a firm, we want to give that firm access to that company's data, without needing to migrate the company onto the same server the accounting firm is already on.
Said another way, as an accountant, your Expensify "Inbox" shows you everything you need to do aggregated across all your clients simultaneously, without needing to "switch" from one client to the next to see if anything needs to be done for each. Sure, there are other ways to do it even if you do shard. But the lack of sharding makes this, and a bunch of other similar kinds of multi-client processing, super easy.
The path to 4 million queries per second
Obviously, SQLite was never designed to do anything like this. But that doesn't change the fact that it does this incredibly well, albeit with a few modifications created by SQLite over the years at our request (we are a very enthusiastic sponsor of the SQLite Consortium, and they've been a tremendous help).
The modifications are open source and available to anyone (just ask them and I'm sure they'll hook you up), and are largely out of scope of this post, but consist of (if I can remember them all):
Disable Posix advisory locks. This prevents you from accessing the same database from an external process (eg, from the command line tool) while the database is running, but that is acceptable for our use.
Make RANDOM() deterministic (for some reason it's non-deterministic by default)
Disable the malloc() global lock (I don't remember why this was there, but apparently not needed for our case)
Extend the maximum size of a memory map
Other minor tweaks like this
In other words, the core design of SQLite was pretty much on point. I don't think people realize how incredible a tool it is.
Rather, most of the effort into optimizing the performance of the system came down to optimizing the BIOS and kernel power settings to eliminate extraneous memory access (eg, disable prefetching) and prevent CPUs self-throttling to conserve power.
The results: Bare metal vs EC2
There's a general conception that EC2 is faster, cheaper, and easier than hosting your own hardware. Maybe I'm old school, but I've never quite subscribed to that notion. The best price you can possibly get on an EC2 server is to prepay for a year with a 3 year commitment, but the price you still pay on day one is equal to the cost of the hardware.
Because think about it: Amazon isn't going to take a chance on you, so they're not going to buy hardware for you unless they get paid up front, and are confident they'll get paid back many times more.
So, you are out the same amount of cash, for the same hardware, except rather than getting five years of solid use — you need to pay that same amount of money five more times (because unlike phones, server hardware doesn't turn into a pumpkin after three years).
EC2 comes at an astonishing premium — perhaps 3-10x the actual hardware cost — which is fine if you value the convenience that much. But what's less known is that it also comes at an enormous performance penalty.
At the time of this writing, the largest EC2 instance you can possibly buy is the x1e.32xlarge, with 128 "vCPUs" and 4TB of RAM. It costs $26.688 per hour, meaning $233K/yr — for a single server. (If you commit to three years and prepay for one, you can get it for "only" $350K for three years.)
Here's how that server compares to what you can host yourself at a fraction of both the upfront and ongoing cost:

The vertical axis shows the total number of Queries Per Second, and the horizontal axis shows how many threads are being used to get that datapoint.
The test is run for 100s for each thread count configuration (eg, 100s with 1 thread, 100s with 2 threads, etc), and the fastest individual second is used as the result. (This is important as it can take a while for the the CPU caches to "warm up" and this filters out the artificially slow samples.) The full performance test can be found on GitHub here.
The query itself just sums a range of 10 rows randomly located inside 10B row (447GB) two column database of random integers, one of which is indexed and the other not. This means that the test is fully cached in RAM, and the database is precached prior to the test. No writes are done during this test, only reads.
Each thread is NUMA aware, meaning all its local memory access is done inside a local memory node, and the database itself is split between the NUMA nodes (though contrary to expectation, NUMA awareness doesn't actually matter much for this test). Everything is done on a stock 16.04 Ubuntu install.
The orange line shows total aggregate performance of the EC2 box capping out around 1.5M queries per second. The blue line shows the same test on a "bare metal" machine, which gets upwards of 4M queries per second and keeps on climbing for the duration of the test. (I only care about 192 threads for the purpose of my test so I didn't worry about going higher.)
The red line shows the same test, but for a 30B row table (1.3TB) — larger than the physical RAM of the bare metal machine.
Observations
First, wow. This is a ton of horsepower. 4M queries per second from a single server is nothing to sneeze at, even recognizing that it's a pretty artificial query to be testing. (If you test "SELECT 1;" it gets about 160M queries per second, but that's even more artificial.)
Second, SQLite scales amazingly, almost out of the box. This test achieves almost perfect linear scalability as we add physical CPUs, and hyperthreading works much better than I expected in eeking out extra capacity after that.
But third, wtf is wrong with EC2? I really assumed 1 vCPU was roughly equal to 1 physical CPU, but man is that wrong. That is really highlighted here:

This is the same basic chart, but this time showing the average performance of each thread, and how that performance changes with thread count. The blue line shows pretty much what I'd expect: per-thread performance stays stable (remarkably so) as new physical cores are activated, but starts to drop as we hit hyperthreading territory.
In fact, this is scaling far more linearly than I expected, as the test is designed in such a way to ensure each CPU is accessing remote RAM 87.5% of the time. This means it's pretty much a worst-case scenario in terms of NUMA access, but it doesn't seem to degrade the performance of the test much at all. Looks like Intel can do something right, and Purley's new memory architecture is pretty solid!
Additionally, the red line shows that even when 25% of the reads go to disk, it has a negligible impact on total performance. I attribute this to the crazy fast access of NVME SSD drives — again, much better than expected.
But the orange line shows that each new thread on the EC2 box comes at a substantial penalty to the others. First, this chart shows pretty obviously that 128 "virtual CPUs" actually means 64 physical CPUs + hyperthreading. That's pretty disappointing and misleading, as I really assumed every vCPU was implied to be equal performance.
More importantly, however, is the curve of that orange line itself. This is easier to see when the test is re-run after replacing the 10-billion row database with a single-row database, to remove memory access from the equation:
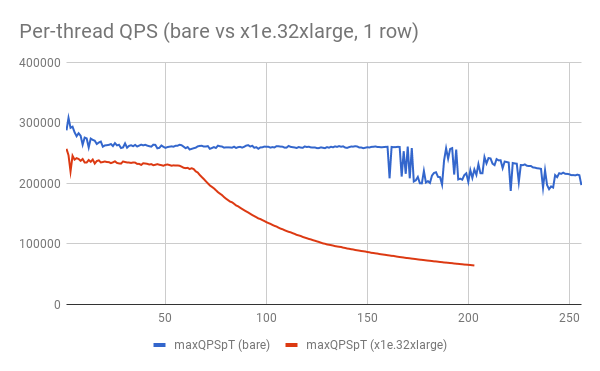
(Please excuse the jagged data, this was run with a shorter period per sample and thus is a bit more noisy, but it gets the point across.)The blue line shows QPS per thread on the bare machine as new threads are added, and as you would expect, it gets perfect linear scalability up to 192 physical cores, and then linearly drops off as hyperthreading comes into play.
The red line is the EC2 box, and performance degrades even before hitting 64 physical cores, but then drops off precipitously after that. Even worse, the curve of that line signals that it's not memory access slowing things down — it's power throttling. Once you get over 64 cores and start hyperthreading, the power consumed by each CPU goes up.
But clearly EC2 has configured things in some kind of "balanced" performance profile, which means the clock speed of the CPU is reduced when the total power consumption gets too high — thereby limiting power consumption at the expense of performance.
This results in a curved performance-per-thread-count profile, which levels off into a linear downward slope at 128 threads because that's the point at which all the 128 CPUs are in use. Once all CPUs are used, threads just compete for a slot — and adding more threads doesn't consume any more power (but it's linear because each new thread takes time away from the existing threads).
It turns out a major hidden advantage of hosting your own hardware is it means you can configure the BIOS to suit your own needs, and in our particular case those changes were everything.
Conclusions
In summary:
Crazy powerful servers are surprisingly cheap to buy (so long as you are hosting your own hardware)
SQLite scales almost perfectly for parallel read performance (with a little work)
NUMA bottlenecks don't seem nearly as big a problem as I theorized
Not all EC2 virtual CPUs are the same, and none of them are remotely as powerful as an actual CPU you host yourself
Epilogue
All this testing was done before Meltdown and Spectre, so I'm not sure how the performance of this test will be impacted. We're running those tests now, and if anybody is interested, I'll write up and share the results. Early indications suggest about a 2.5% reduction in performance, but more work remains to be done.
Additionally, though this test was focused on read performance, I should mention that SQLite has fantastic write performance as well. By default SQLite uses database-level locking (minimal concurrency), and there is an "out of the box" option to enable WAL mode to get fantastic read concurrency — as shown by this test.
But lesser known is that there is a branch of SQLite that has page locking, which enables for fantastic concurrent write performance. Reach out to the SQLite folks and I'm sure they'll tell you more!







